
Data voor effectieve besluitvorming in de transitiefase
8 MEI 2020
Alessandro Bozzon, Geert-Jan Houben
De coronacrisis heeft twee kernaspecten van besluitvorming in crisistijd onder de aandacht gebracht: de centrale rol van gegevens en de behoefte aan deskundige kennis en oordeelsvorming. Tijdens de inperkingsfase heeft de overheid beleidsbesluiten als de intelligente lockdown genomen op basis van adviezen van epidemiologen en gedragswetenschappers. Hun advies was gebaseerd op informatie over bevestigde infecties, ziekenhuisopnames en sterftecijfers: gegevens die vaak onvolledig waren of met vertraging werden gerapporteerd. Deze onzekerheid was van invloed op de uitkomsten van de gebruikte epidemiologische modellen, zodat de expertise en afwegingen van deskundigen een extra grote rol speelden bij het invoeren van landelijke maatregelen zoals het sluiten van bioscopen en kappers.
Verandering van paradigma
Voor een succesvolle overgangsfase is een verandering van paradigma nodig. Beleid en interventies zullen moeten worden gebaseerd op allerlei afwegingen, bijvoorbeeld volksgezondheid versus bedrijfsleven. Ze zullen vervolgens lokaal worden toegepast, eventueel voor specifieke economische sectoren. Welke regio's, steden, buren of straten moeten (opnieuw) gesloten worden? Welke scholen, verpleeghuizen of treinstations? Wanneer en voor hoe lang? Om zulke vragen te kunnen beantwoorden, hebben we accuraat en overkoepelend, maar ook lokaal inzicht nodig in de verspreiding van het virus over het land.
Landelijke gegevensverzameling
Om de overgangsfase succesvol te laten zijn, moeten we op landelijk niveau gegevens kunnen verzamelen. Gegevens over het optreden van symptomen, bevestigde infecties en herstelde patiënten, moeten we samenvoegen met informatie over uitgevoerde testen, demografische gegevens, gezondheidsrisico's, en mobiliteitsgegevens. Die informatie moet dan afkomstig zijn van betrouwbare partijen en verkregen via gecontroleerde processen; hij moet van hoge kwaliteit zijn, maar toch anoniem om de privacy op grond van de AVG te garanderen.
Die informatie kan dan worden gebruikt voor dashboards die op lokaal niveau, bijna realtime, inzicht geven in gebieden waar een potentiële uitbraak plaatsvindt of waar kwetsbare mensen wonen. Wij geloven dat een dergelijke infrastructuur haalbaar is, maar onze ervaring met grootschalige data-acquisitie leert, dat je daarbij drie principes moet hanteren:
- Doorbreek datasilo's
- Betrek mensen op grote schaal
- Zoek naar blinde vlekken in je gegevens
Doorbreek gegevenssilo's
Nederland loopt al jaren voorop in de digitale transformatie van de samenleving en de gezondheidssector. Tegelijkertijd komen steeds meer gegevens beschikbaar voor gebruik door onderzoekers en het grote publiek. Toch worden gegevens nog steeds beheerd en verwerkt in silo's, waarbij een hoge mate van versnippering leidt tot problemen als je data wilt integreren. Oplossingen die nu worden gebruikt voor datawetenschap in de stad (Urban Data Science) kunnen helpen om risico's en kwetsbaarheden op een privacy-bewuste manier zichtbaar te maken. Daarvoor moeten we dan wel het fenomeen van datasilo's tussen verschillende organisaties doorbreken en de integratie van verschillende databronnen faciliteren.
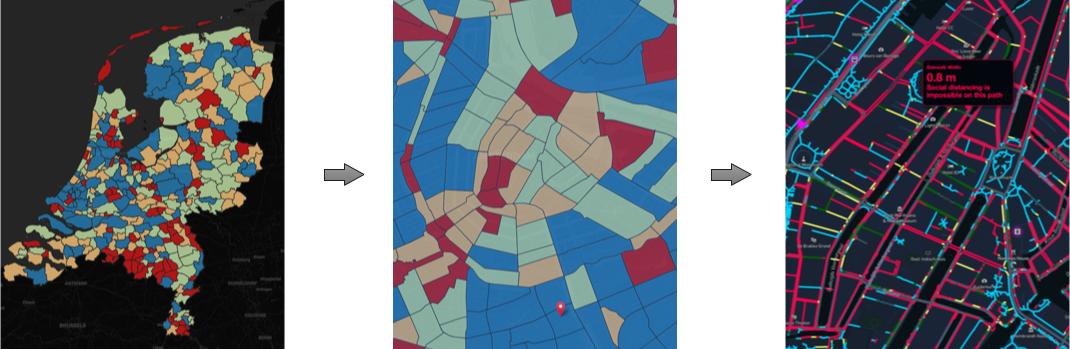
Figuur 2 toont een prototype van een interactief dashboard dat momenteel in ontwikkeling is bij onze onderzoeksgroep. Hiermee kun je gegevens uit meerdere databronnen samen te voegen, zoals:
- gegevens over vastgestelde infecties, ziekenhuisopnames en sterftecijfers (verstrekt door de GGD)
- gegevens over vroege symptomen (die door het NIVEL in geanonimiseerde vorm via het nationale huisartsennetwerk en met instemming van patiënten kunnen worden verstrekt)
- demografische gegevens (bijvoorbeeld van het CBS)
- geodata van de Basisregistratie Grootschalige Topografie (BGT)

Figuur 2: Beeld van het project Social Distancing & The City (credits: Dr. Achilleas Psyllidis) - social-glass.tudelft.nl/social-distancing/
Met behulp van nationale mobiliteitsonderzoeken en geanonimiseerde chipkaartgegevens kunnen we locaties en patronen bestuderen waar en wanneer veel mensen samenkomen. Geavanceerde detectietechnieken (bijv. het SmartStation-concept, afbeelding 3) kunnen een zeer gedetailleerd beeld geven van verkeers- en reispatronen (in real-time), op een manier die voldoet aan de AVG-normen.
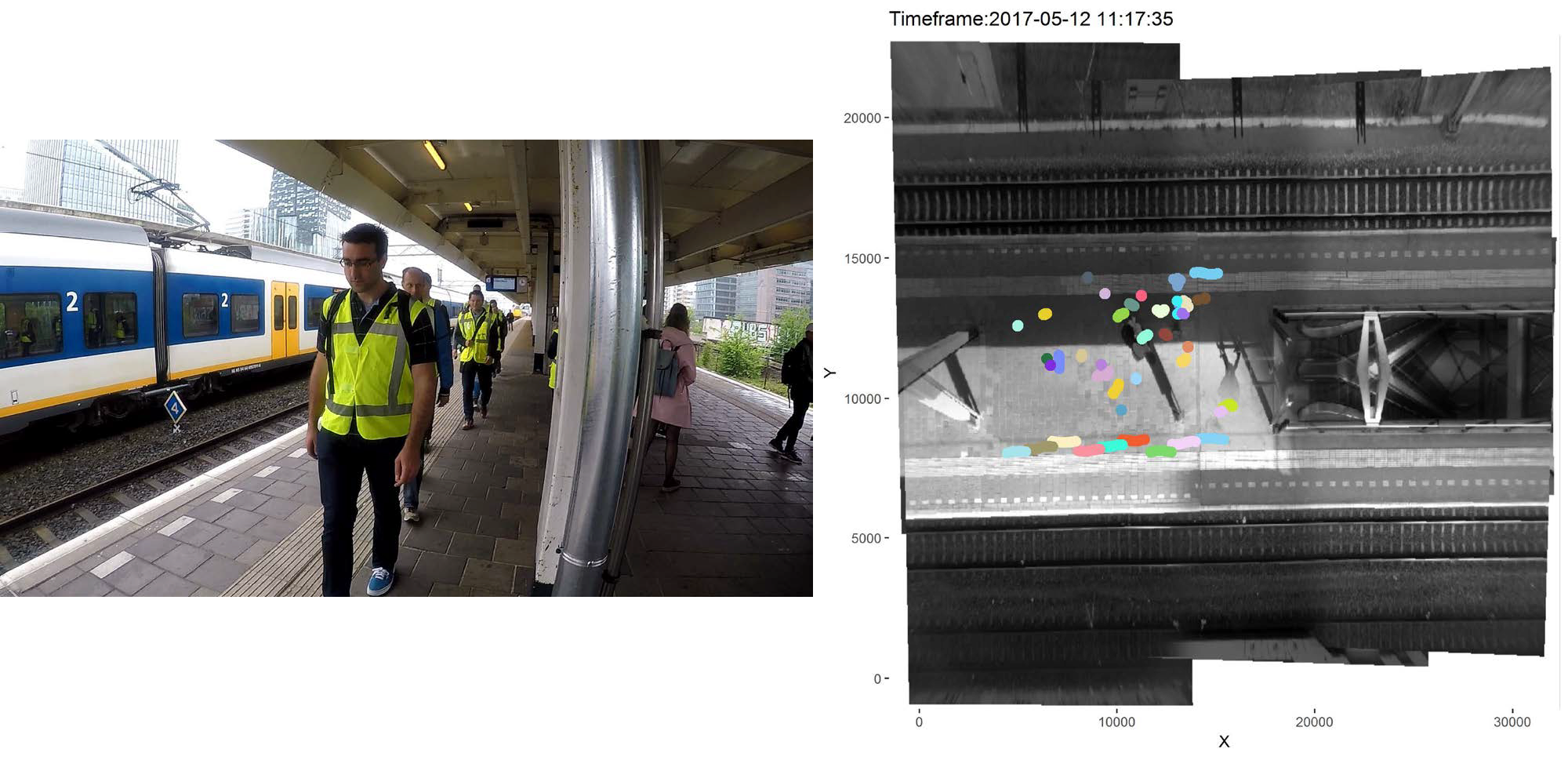
Koppel je zulke gegevens, dan ontstaat een gedetailleerd model van de stedelijke omgeving. Je kunt dat model bijvoorbeeld gebruiken om te beoordelen of er in bepaalde voetgangersgebieden voldoende afstand kan worden gehouden door de verschillende gebruikers, waaronder rolstoelgebruikers. Je zou het ook kunnen gebruiken om looproutes waarbij voldoende afstand kan worden gehouden te ontwerpen. Het vraagt wel om een gecoördineerde inspanning om alle benodigde gegevens met een hoge frequentie, misschien wel op dagelijkse basis, te verzamelen, anonimiseren en integreren.
Benut menselijke capaciteit
Testen en contactonderzoek zijn ons krachtigste wapen tegen het virus. Maar zelfs als we grootschalig kunnen testen kan niet elke burger met regelmaat worden getest. Het in kaart brengen van hoe en waar het virus zich verspreidt en het opsporen van mensen die mogelijk geïnfecteerd zijn, zijn tijdrovende processen. Naar schatting zit er voor elk onderzocht geval ten minste 24 uur werk aan vast voor meerdere operators, omdat patiënten meerdere keren moeten worden geïnterviewd (persoonlijk en per telefoon).
Duizenden tracers nodig
Apps om de verspreiding van het virus te volgen hebben allerlei tekortkomingen, van privacyrisico's tot beperkte adoptie. Je kunt alleen nauwkeurige resultaten krijgen als je mensen het contactonderzoek laat uitvoeren. Dit vereist namelijk gevoeligheid, intuïtie, vindingrijkheid, intelligentie en bekendheid met het betrokken gebied en misschien ook met de getroffen personen. Deze taak vereist wel grootschalige coördinatie van duizenden tracers: individuen die je moet trainen in en ondersteunen bij het verzamelen van gegevens. Je moet ook op hun oordeel kunnen vertrouwen en ze de privacy van de betrokken mensen kunnen toevertrouwen. Technologie voor Human-Centered Artificial Intelligence en Crowd Computing kan de opsporingsactiviteiten helpen opschalen en versnellen, met behoud van de kwaliteit van het handmatige proces.
Hybride mens-machine-werkprocessen kunnen helpen
Systemen die zijn ontworpen voor het op grote schaal verwerken van gegevens kunnen de contactonderzoekers ondersteunen. Denk aan aanbevelingssystemen als van Netflix of Spotify, die je kunt gebruiken om de planning en toewijzing van taken te begeleiden. Chatbots of andere dialoogsystemen kunnen contactonderzoekers helpen met hun interviewworkflows en ze toegang tot relevante kennis verschaffen. Er bestaan ook systemen voor de controle van hybride mens-machinewerkprocessen en de kwaliteit van gegeven. Die kunnen worden ingezet bij de opleiding en de beoordeling van nieuwe, eventueel uit lokale gemeenschappen gerekruteerde, contactonderzoekers. Op die manier kan de opsporingscapaciteit aanzienlijk worden vergroot met behoud van kwaliteit en snelheid.
Zoek naar blinde vlekken in gegevens
Een bekend probleem in de datacentrische wetenschappelijke disciplines is dat van de Dark Data, dat wil zeggen gegevens die niet zijn vastgelegd en die toch een grote invloed kunnen hebben op inzichten, beslissingen en acties. In de inperkingsfase kwamen verschillende problemen naar voren met zulke Dark Data, vooral in de vorm van gegevens waarvan we wisten dat ze ontbraken (zogenaamde bekende onbekenden). Voorbeelden zijn representatieve cijfers over de daadwerkelijke verspreiding van de besmetting vanwege beperkte testcapaciteit, of nauwkeurige statistieken over COVID-19-gerelateerde sterfgevallen buiten de ziekenhuizen. Onzekerheid over deze gegevens hebben ook nu nog invloed op het modelleren van het verloop van de epidemie. Omdat de data slechts een gedeeltelijk beeld van de werkelijkheid konden geven, waren kennis en oordeelsvorming van deskundigen cruciaal bij het bepalen van de strategie in Nederland. Tegelijkertijd hadden gegevens waarvan we niet wisten dat ze ontbraken (zogenaamde onbekende onbekenden) een onvermijdelijk maar duidelijk effect.
Participatieve besluitvorming
Om de overgangsfase goed door te kunnen komen, moeten we ons meer bewust worden van blinde vlekken in onze gegevens en die op een efficiënte en tijdige manier aanpakken. Daarvoor moeten we een groeiende pool van kennis en expertise aanboren, eventueel door besluitvormingsprocessen meer participatief te maken. We denken daarbij aan wetenschappers uit andere disciplines zoals netwerk- en datawetenschap en kunstmatige intelligentie, maar ook professionals uit de gezondheidszorg. Ook de bredere samenleving, waaronder ondernemers en burgers, moet een stem hebben in de besluitvorming over de vormgeving van de anderhalvemetersamenleving. Human-Centered Artificial Intelligence en Crowd Computing-technologie kunnen ook hier helpen bij de interactie tussen de verschillende maatschappelijke belanghebbenden.
Samenvattend zijn wij van mening dat er een duidelijke behoefte is aan een fijn vertakte landelijke infrastructuur voor het verzamelen van data ten behoeve van schaalbare besluitvorming in de overgangsfase na de coronacrisis. Op basis van onze ervaring stellen we drie belangrijke ontwerpprincipes voor en pleiten we voor het gebruik van state-of-the-art wetenschap en technologie op het gebied van de stedelijke datawetenschap, mensgerichte kunstmatige intelligentie en crowd computing.
Prof. dr. ir. Alessandro Bozzon
Alessandro Bozzon is gespecialiseerd in mensgerichte artificiële intelligentie (AI). Hij kijkt onder andere naar welke informatie nodig is om bijvoorbeeld drukte in de stad te voorspellen en te reguleren. Gecombineerd met zijn expertise op het gebied van het combineren van verschillende data geeft hij beter inzicht in de verspreiding van het coronavirus, en de lokale effecten van verschillende maatregelen.
Meer informatie
Artikel ‘Datawetenschap met een eigen draai’

Prof.dr.ir. Geert-Jan Houben
Geert-Jan Houben is gespecialiseerd in (big) data. Hij ontwikkelt nieuwe methoden om grote hoeveelheden gegevens te kunnen opslaan, verbinden en verrijken, en zo complexe patronen daarin snel te kunnen vinden en analyseren voor inzicht en besluitvorming. Houben en collega’s passen deze kennis nu toe op inzichten in de verspreiding van het coronavirus, en de effecten van de verschillende maatregelen.
