
Navigating the Transition Phase
Human-in-the-Loop Approaches for Accurate and Timely Data Acquisition for Scalable Decision Making
Alessandro Bozzon, Geert-Jan Houben
The COVID-19 emergency put a spotlight on two core aspects of decision-making in times of emergency: the central role of data and the need for expert knowledge and judgment. During the containment phase, the government enforced policies like the intelligent lockdown based on the advice of epidemiologists and behavioural scientists. The advice was informed by data about reported infections, hospitalisations, and mortality; data that was often incomplete or reported with delays. This uncertainty heavily impaired the effectiveness of standard epidemiological models, so the sensibility and expertise of scientists played a key role, and interventions –like closing cinemas and hairdressers – were applied country-wide.
Change of paradigm
A successful transition phase will require a change of paradigm. Policies and interventions will be based on trade-offs between a plurality of considerations (e.g. public health vs. business) and will be applied at a local scale, possibly for specific economic sectors and business functions. Which regions, cities, neighbours, or streets will need to be controlled or closed (again)? Which specific schools, nursing homes, or train stations? How soon, and for how long? Effective decision making will require actionable, accurate, holistic yet local, and timely insights about the status of the virus spreading in the country.
Nation-wide data acquisition
For the transition phase to be successful, a capillary nation-wide data acquisition capability needs to be in place, where data about the appearance of early symptoms, confirmed infections, and recovery is fused with infection tracing data, demographic and health-risk data, and mobility data. The data should be acquired through trusted parties and well-controlled processes; it should be of high-quality, yet anonymous and minimal, to guarantee the privacy of the involved individuals according to GDPR regulations. This data could be used to feed risks and vulnerabilities dashboards that can provide insights at the local level, possibly in near real-time, about areas where either there is a potential outbreak or where vulnerable people live. We believe that such an infrastructure and capability is feasible, but as our experience with large scale data acquisition campaigns suggests, at least three principles should guide its development:
- Break data silos
- Empower and exploit human intelligence at scale
- Look for blind spots in your data
Break data silos
The Netherlands has been spearheading the digital transformation of its society and its health sector for many years. At the same time, open and FAIR data principles have been making an increasing amount of data accessible to researchers and the broader public. Yet, data are still managed and processed in silos, with high fragmentation that leads to issues of integration. Urban Data Science solutions can be put to work to develop risks and vulnerabilities maps, in a privacy-preserving fashion, by breaking down data silos between different organisations, and by facilitating the integration of different data sources.
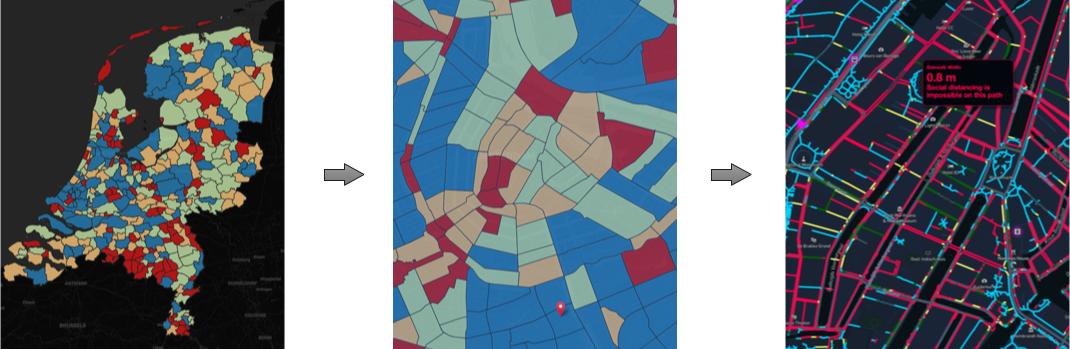
Figure 2 depicts an example of a prototype interactive map-based system and dashboard currently under development in our research group. It is capable of fusing data from multiple data sources, including:
- data from official infections, hospitalisations, and mortality data (provided by the GGD)
- early symptoms data (that could be provided by NIVEL in an anonymised form through the national GP network and consenting patients)
- demographic microdata (e.g. from CBS)
- geo-data from the Basisregistratie Grootschalige Topografie (BGT)

Figure 2: Image from the Social Distancing & The City project (credits: Dr. Achilleas Psyllidis) - http://social-glass.tudelft.nl/social-distancing/
With the help of national mobility surveys and anonymised chip card data we can study patterns and locations where many people come together.
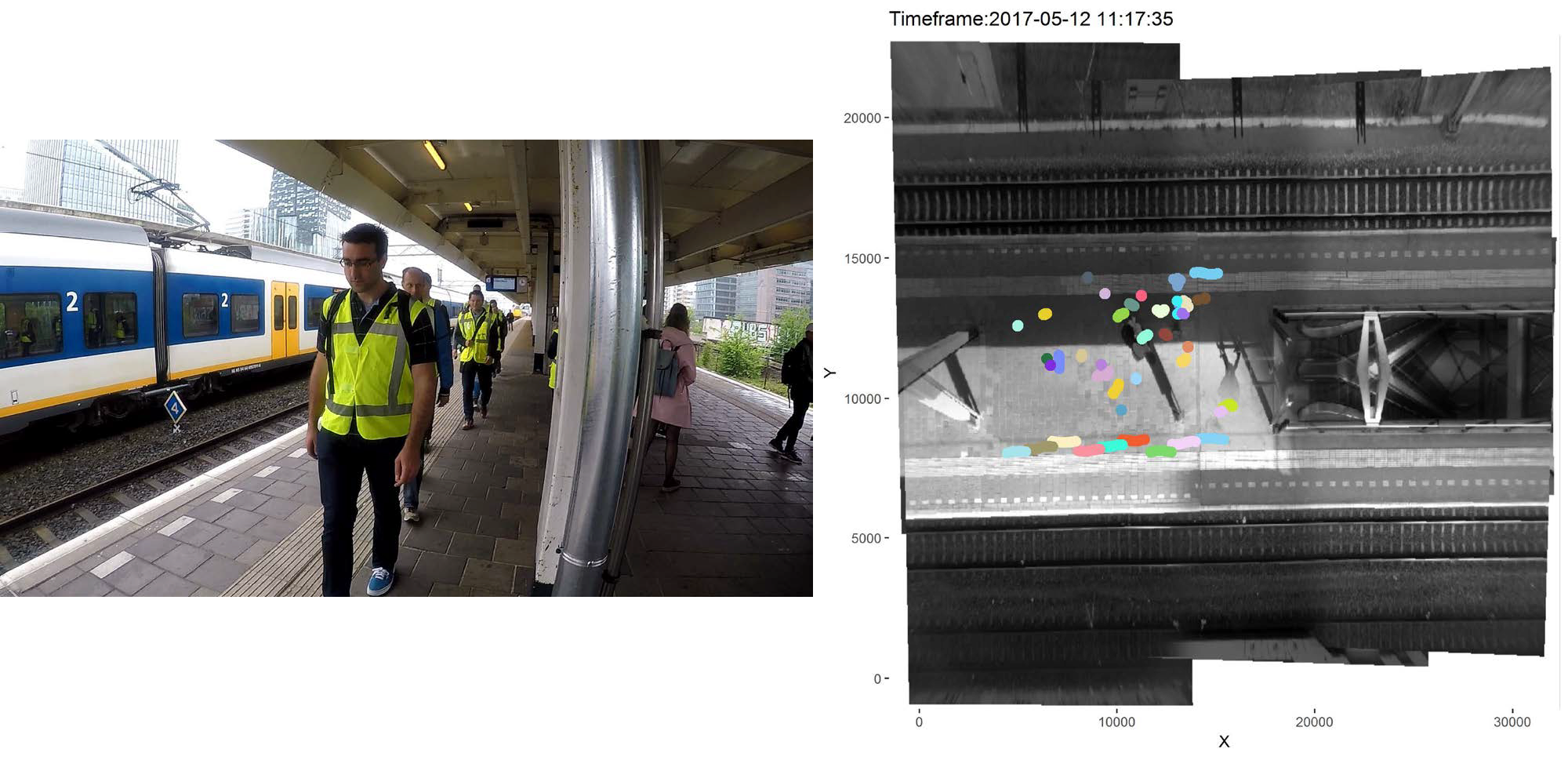
Advanced sensing techniques (e.g. the SmartStation concept, Figure 3) can be used to provide a very detailed picture of traffic and travel patterns (in real-time), in a GDPR-compliant fashion.
Linking these data will provide us with a highly detailed spatio-temporal model of the urban environment where risks and vulnerabilities can be highlighted and analyzed. The model can be used, for instance, to assess the suitability of pedestrian spaces with respect to social distancing rules for different categories of people (e.g. wheelchair users), or to enable novel routing services that account for social distancing as optimisation criteria. However, a coordinated effort is needed to facilitate the acquisition, anonymisation, and integration of all these data with a higher frequency – up to a daily basis.
Empower and exploit human intelligence at scale
The three T’s approach (test, track, and trace) is our most powerful weapon against the virus. Testing can be performed at scale, but there will always be capacity limitations – not every single citizen can be tested with regularity. The processes of tracking how and where the virus is spreading and of tracing people who may be infected, are also time-consuming and high-latency activities. Estimates project that at least 24 hours of work of multiple operators is required for each single investigated case, as patients need to be interviewed multiple times (in person and by phone).
Thousands of tracers needed
Tracing apps suffer from abundant shortcomings, from privacy risks to limited adoption. Accurate results could only be obtained through human investigative work, a task that requires human sensibility, intuition, ingenuity, intelligence, and contextual knowledge about the area tracked and, possibly, the people affected. This task requires large scale coordination of thousands of tracers, individuals that need to be trained and supported in their data collection endeavours, and that need to be trusted with their judgment and with the privacy of the involved people. Here, technology developed in the field of Human-Centered Artificial Intelligence and Crowd Computing can help with scaling up the tracing capabilities of our country, by helping to accelerate tracing activities in scale and time, while preserving the inherent quality of the manual process.
Human-machine workflows can help
Coordination and interaction tools designed for handling data collection at web-scale can be employed to support tracers with their investigative activities. For instance, recommender systems similar to the ones from Netflix and Spotify can be used to guide the planning, splitting and assignment of tracing tasks, in line with national and local track and tracing requirements (guided, for instance, by specific epidemiological questions). At the same time, conversational agents and chatbots can assist tracers with their interview workflows and facilitate their access to relevant knowledge. Sophisticated data quality control mechanisms and hybrid human-machine workflows can support the on the job training and assessment of new tracers, possibly recruited from local communities, thus significantly augmenting tracing capacity while guaranteeing quality and timeliness.
Look for blind spots in your data
A well-known issue in data-centric scientific disciplines is the problem of Dark Data, that is data that has not been recorded, and yet can have a major impact on insights, decisions, and actions. The containment phase surfaced several issues with dark data, especially in the form of data that we knew was missing (so-called known unknowns): for instance, representative figures about the actual spread of the contagion due to testing capacity limitations; or accurate statistics about COVID-19 related deaths outside of hospitals. Uncertainties about these data impacted our ability to model the course of the disease, also in the near future. Expert knowledge and judgement have been crucial in setting the course of the country, as data could provide only a partial view of reality. At the same time, data that we did not know we were missing (so-called unknown unknowns) had an unavoidable but obvious effect.
Participatory decision-making
To navigate the transition phase, we will need increased awareness of existing data blind spots that would need to be addressed in an efficient and timely manner. To this end, it will be important to tap on an increasing pool of knowledge and expertise, possibly by making the decision-making processes more participatory. In addition to scientists from other disciplines (e.g. network science, data science, artificial intelligence), health care professionals and, to some extent, members of the wider society (including business owners and citizens) should have a voice in imagining and designing our future life. Once more, Human-Centered Artificial Intelligence and Crowd Computing technology can facilitate the interaction between different societal stakeholders, enable articulated yet framed discussions (at scale), and help in synthesizing common approaches and proposed solutions.
To conclude, we believe there is an obvious need for a capillary nation-wide data acquisition infrastructure, necessary to facilitate scalable decision-making in the context of the transition phase following the COVID-19 emergency. Based on our experience, we propose three key design principles and advocate the use of state-of-the-art science and technology in urban data science, human-centred artificial intelligence and crowd computing.
Prof. dr. ir. Alessandro Bozzon
Alessandro Bozzon specialises in human-centred artificial intelligence (AI). Among other things, he looks at the information that is needed to predict and regulate e.g. crowds in the city. This expertise, as well as his experience in combining different data sources, he is now turning to help improve our insights into the spread of the coronavirus, and the local effects of different measures.
More information

Prof.dr.ir. Geert-Jan Houben
Geert-Jan Houben specialises in (big) data. He develops new methods for the storing, connecting and enriching large amounts of data, in order to quickly find and analyse complex patterns in order to gain insights and aid decision-making. Houben and colleagues are now apply this knowledge to provide new insights into the spread of the coronavirus, and the effects of the various measures.
