Research
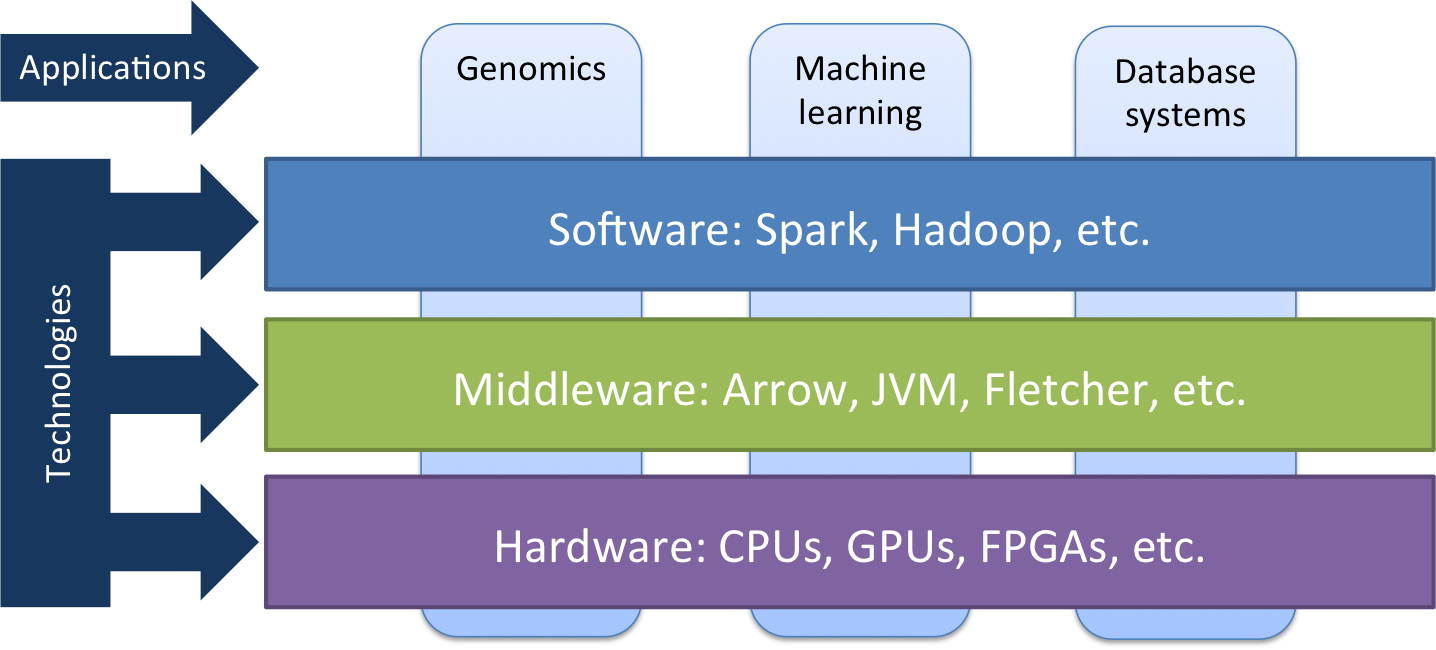
Technologies
Research in our group focuses on a number of horizontal technology layers in the big data stack. At the top layer, we perform optimizations and increase the efficiency of software developed using big data frameworks such as Apache Spark. In the middleware layer, we develop efficient interfaces such as Apache Arrow to allow software components (such as JVM) to communicate efficiently with the hardware. And at the hardware layer, we develop optimized CPU or GPU implementations in addition to customized FPGA IP.
Application domains
We use these technologies to target multiple application domains, focussed on genomics, machine learning and database systems. The field of genomics and personalized medicine is becoming extremely data-driven. This is due to the dramatic decrease in the price of DNA sequencing in the past decade, which resulted in shifting the bottleneck in DNA analysis from acquiring the DNA data to the actual processing and analysis of this data. Our group is working to streamline the whole genomic computational pipeline starting from data storage and transfer, all the way to data analysis and interpretation. Important collaborators in this field are Utrecht University Medical Center, Erasmus Medical Center and our own startup Bluebee.
Another application domain the group focuses on is machine learning, which is becoming a central theme in the analysis of big data volumes. Collaborations between our group and a number of industrial partners have shown the viability of machine learning algorithms in various applications ranging from predictive maintenance to fraud detection. In addition, Spark is being used to enable the reliable in-memory computation of big data volumes, thereby reducing the bottleneck incurred by hard disk access for memory intensive tasks. A whole host of big data database systems (such as Cassandra and MongoDB) are being developed to manage the continuously increasing volumes of data. Important collaborators in this field are IBM, Philips Healthcare and Leiden University Medical Center.