Blog 1: Cassandra’s curse
Nick van de Giesen
This is the first blog of a series of blogs by the scientists of the Water Resources Management group of TU Delft. Most first blogs promise to be the first of many; the start of a consistent line that will document the scientific interests and progress of our group.
Unfortunately, the predictive power of first blogs is very limited, a fact that has been scientifically well documented (see for example ‘Blogger, stick to your story. Modeling Topical Noise in Blogs with Coherence Measures’). So let me just write about something that is at the center of recent research activity, and not try to predict the future of this part of the blogosphere.
eWaterCycle
I would like to talk briefly about prediction, hence the title. At the EGU General Assembly in Vienna, April 2014, we launched the eWaterCycle’s global hydrological prediction system. You can look at the system at forecast.ewatercycle.org. You can zoom in on any part of the world and, per pixel, a prediction of up to ten days of the runoff will be shown. It is a pretty smart system, especially because the actual costs to build it were very low, in the bigger scheme of things. The global model is basically the PCR-GLOBWB model developed at Utrecht University. This was adapted by the eScience Centre in Amsterdam so it could run in High Performance Computing environments. At TU Delft, we focus on operational aspects, especially Data Assimilation (see the recent publication “Reduction of Used Memory Ensemble Kalman Filtering (RumEnKF): A data assimilation scheme for memory intensive, high performance computing”). What is smart about the development is that to a large extent use is made of existing standards and software. As Niels Drost, the eScience engineer of the project proudly said in Vienna: We did not write one line of code! That was not 100% true but close enough and strongly different from the many attempts to build new model platforms.
Predictions
Once the model was running, be it in still very much in a beta fashion, it was only natural to start clicking away and look for familiar places. For example, Rolf Hut, who spent time in Kenya as a student, sent me a mail on 26 April, basically saying: look, the Mara river seems to be flooding soon. That is, of course, interesting but at that time that information was just some bits and bytes on a computer. Yet, on May 8, the Daily Nation reported on the previous week’s flooding in Narok by the Mara River, causing 13 deaths and 7 people missing. Should we have called someone? But we only have a beta version…
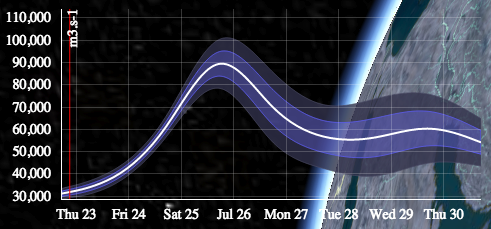
When I submitted our eWaterCycle abstract for the 2015 AGU conference, I thought it would be good to add a picture of the forecasting screen (see below). The default position of the cursor is pointing at the Ayeyarwady, in honor of my attempt to win an Oscar for best short dramatized hydrological prediction system documentary.
There was a nice looking hydrograph associated with it but I did not give it any additional thought. Then, a week later, sure enough there was a 20 years flood in Myanmar. We had predicted 90,000 m3/s at the peak, whereas in reality the flood peaked at 60,000 m3/s. This over-prediction was due to a bug, now fixed, that added a positive bias to the input signal. This bug aside, we did predict a flood. I visited Myanmar in August this year and learned that flood warnings were available only a few days in advance.
Cassandra
So, like Casandra, we seem to be able to look into the future. Nobody believed Casandra’s predictions, which was her curse. But what can we do with a system that we just started to test on accuracy? Should we build an alarm system and send out warnings as soon as a flood is predicted? Or do the scientifically correct thing and test the true accuracy before we start calling people around the globe?